You must log in or # to comment.
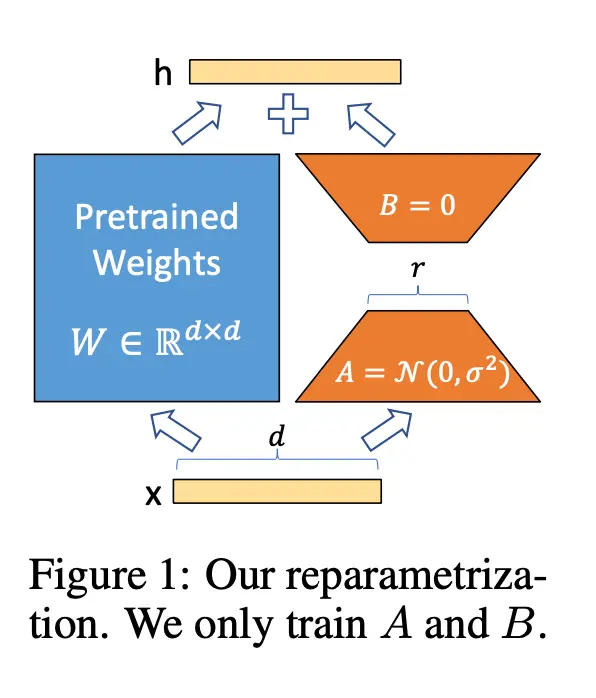
LoRA fine tuning is an incredibly simple idea. For each matrix you want to fine-tune, introduce a low rank matrix ΔW = BA where the inner dimension is r << d, and compute (W + ΔW)x. Freeze all pretrained parameters and only update B and A. B is initialized to 0 so that the initial model is equal to the pretrained model. After training, you can also write V = W + ΔW to preserve latency.
Saved you a click.
Well now I feel almost obligated to click - is the part of the title “deep dive” completely misleading or is the post really just a LoRA explanation?
I’d like to think we dove deep, but let me know!