
- cross-posted to:
- technology@lemmy.zip
- technology@lemmy.world
- cross-posted to:
- technology@lemmy.zip
- technology@lemmy.world
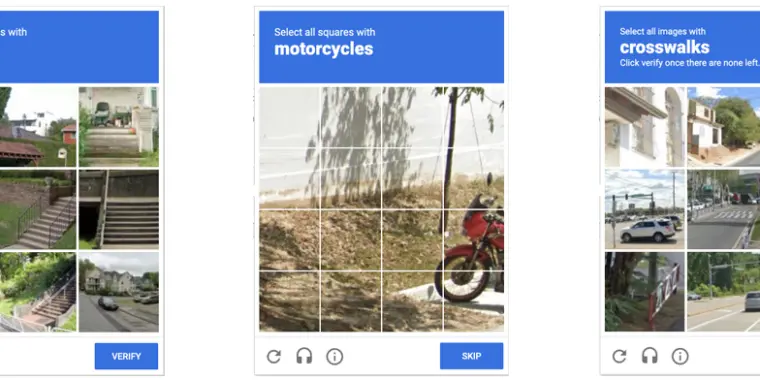
Anyone who has been surfing the web for a while is probably used to clicking through a CAPTCHA grid of street images, identifying everyday objects to prove that they’re a human and not an automated bot. Now, though, new research claims that locally run bots using specially trained image-recognition models can match human-level performance in this style of CAPTCHA, achieving a 100 percent success rate despite being decidedly not human.
ETH Zurich PhD student Andreas Plesner and his colleagues’ new research, available as a pre-print paper, focuses on Google’s ReCAPTCHA v2, which challenges users to identify which street images in a grid contain items like bicycles, crosswalks, mountains, stairs, or traffic lights. Google began phasing that system out years ago in favor of an “invisible” reCAPTCHA v3 that analyzes user interactions rather than offering an explicit challenge.
Despite this, the older reCAPTCHA v2 is still used by millions of websites. And even sites that use the updated reCAPTCHA v3 will sometimes use reCAPTCHA v2 as a fallback when the updated system gives a user a low “human” confidence rating.
Well yeah, I’d hope so, that’s the entire point.
Catcha’s data collection always was with the intent for training ai on these skills. That’s “the point” of them.
It’s reasonable to expect that the older version of captchas can now be beaten by modern ai, because they’re often literally trained on that exact data to beat it.
Captcha effectively is free to use on websites as a tool because the data collection is the “payment”, they then license that data out to people like OpenAI to train with for stuff like image recognition.
It’s why ai is progressing so fast, captchas are one of humanity’s long term collected data silos that are very full now.
We are going to have to keep progressing the complexity of catches as it will be the only way to catch modern AIs, and in turn it will collect more data to improve it.
Yeah, my understanding is that these capchas were made to harvest data to use for AI/Autopilot driven cars. That’s why they are always having you identify motorcycles, bycicles, crosswalks, stoplights, busses, etc. It’s all stuff that automatic driving cars have had a hard time identifying.
I wanted to use 4chan alot before I came here, but FUCK that slider capcha. I bailed after the first time I didn’t pass.
I am relatively confident that you are one of the first people to ever type that sentence out.
I reread his comment three times because I was convinced I must have read it in error somehow.
4chan is more than /b/ and /pol/, you know. The porn boards are pretty good at least
I think I’m good on that, but you do you m8.